Blog
Learn how to scrape the web and create tools with public data.

Serp Robots 101: Navigating the World of Search Engine Crawlers
Embark on a journey through the world of SERP robots and search engine crawlers. Discover their role in SEO and how to optimize your site for these digital explorers.

What is a Private Proxy?

How to Add Description on Google Search for a Shiny App
Optimize your Shiny App for Google with SEO best practices, ensuring your data-rich app reaches and engages the right audience effectively.
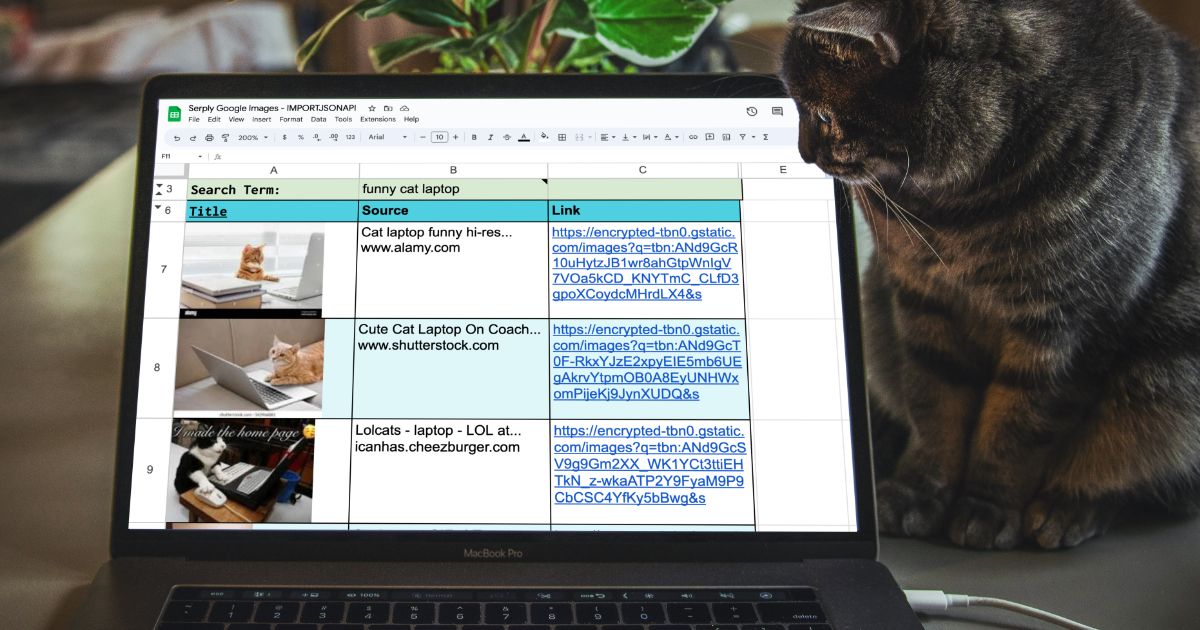
Import API data to Google Sheets
With examples using Hashnode, Openai image generation, Serply Google news and images.

499 Status Code
HTTP Status Code 499, unique to nginx, indicates a client closed the request before a server response. Learn about this non-standard code.

How to Scrape Data from Google Maps: A Step-by-Step Guide

How to follow redirects using cURL?
Learn to manage HTTP redirects with cURL, including handling credentials, maintaining POST methods, and navigating HTML or JavaScript redirects.

What is XPath in Selenium?
XPath is a language that is used for navigating through an XML document, such as an HTML page. In the context of Selenium, XPath can be used to locate elements on a web page, enabling you to find the elements you want to interact with and perform actions on them. In this article, we cover how to use xpath in Selenium.

SERP Site Links for Enhanced Visibility
Unlock the power of SERP site links for your website. Learn how to optimize, implement, and leverage these links for enhanced visibility and improved user experience in search engine results.

Extracting Extensive Data from Google SERP API: A Step-by-Step Guide
Maximize SEO data beyond Google's SERP API 100-result limit with Python tricks or effortlessly with Serply.io's expansive data solutions.